Tesla this week shared more information about its upcoming Dojo supercomputer and revealed some of the hardware that will make up the exascale system.
Since 2019 Tesla CEO Elon Musk has periodically tweeted about Dojo, a ‘neural network exaflop supercomputer,’ but has shared few details up to this point.
During its AI Day event this week, the electric car and energy company revealed its in-house D1 chip that will power the system and a ‘training tile’ module.
Ganesh Venkataramanan, Tesla’s senior director of Autopilot hardware and lead of Project Dojo, said the 7nm D1 chip was designed in-house specifically for machine learning and to remove bandwidth bottlenecks.
Each of the D1’s 354 chip nodes reportedly has one teraflops (1,024 gflops) of compute. Venkataramanan said the entire chip was capable of up to 363 teraflops of compute as well as 10tbps of on-chip bandwidth/4tbps of off-chip bandwidth.
“There is no dark silicon, no legacy support, this is a pure machine learning machine,” he said. “This was entirely designed by Tesla team internally, all the way from the architecture to the package. This chip is like GPU-level compute with a CPU level flexibility and twice the network chip-level I/O bandwidth.”
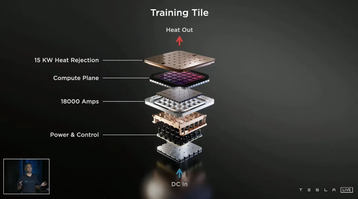
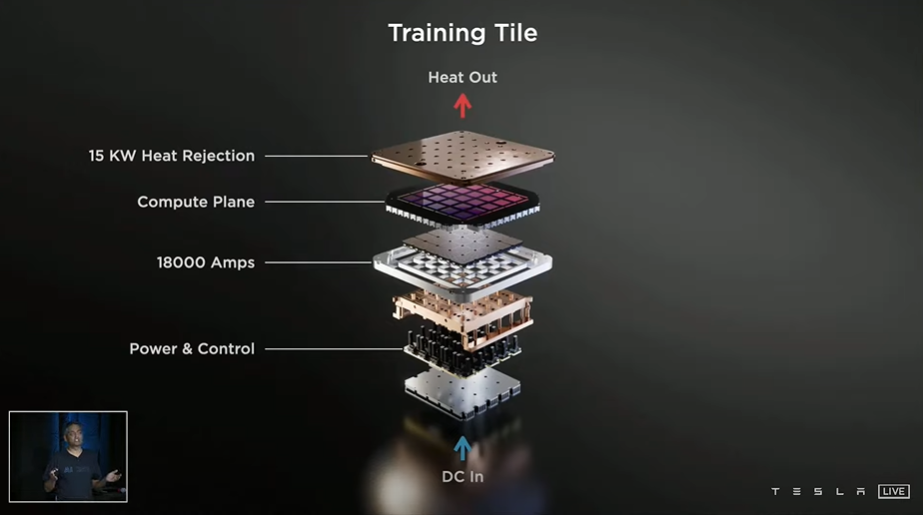
To house the chips, the company has developed what its calls ‘training tiles’ with which to build its computing systems. Each tile consists of 25 D1 chips in an integrated multi-chip module, with each tile providing nine petaflops of compute and 36tbps of off-tile bandwidth.
Venkataramanan said the first training tile was delivered and tested last week. To create Dojo, the company says it plans to install two trays of six tiles in a single cabinet, for 100 petaflops of compute per cabinet. Once complete, the company will have a single ‘Exapod’ capable 1.1 exaflops of AI compute via 10 connected cabinets; the entire system will house 120 tiles, 3,000 D1 chips, and more than one million nodes.
Musk said the system will be operational next year.

{kind=link}
{kind=link}
Even without Dojo, Tesla's existing HPC capabilities are substantial. In June, Andrej Karpathy, senior director of AI at Tesla, discussed the details of an unnamed pre-Dojo supercomputer the company is using.
This cluster, one of three the company currently operates, has 720 nodes, each powered by eight 80GB Nvidia A100 GPUs totaling 5,760 A100s throughout the system. Based on previous benchmarking of A100 performance on Nvidia’s own 63 petaflops Selene supercomputer, 720 sets of eight-A100 nodes could yield around 81.6 Linpack petaflops; which would place the machine fifth on the most recent Top500 list.
During this week’s event, the company said it currently has around 10,000 GPUs across three HPC clusters; as well as the previously mentioned 5670 system which is used for training, it has a second, 4032 GPU system for training and a 1752 GPU system for auto-labeling.
This week’s AI event also saw the company reveal its concept for a 5’8” humanoid robot known as the Tesla Bot. A prototype is expected sometime next year.