本レポートは、2022年9月26日にARK社のHPに公開された、英語による「Newsletter #335」の日本語訳です。内容については英語による原本が日本語版に優先します。また、情報提供のみを目的としたものです。
1. ロケット再利用までのターンアラウンドタイムは、 ファルコン9の第一段の改修費用が過去5年間で約1,300万米ドルから100万米ドルに減少したことを示唆
By Sam Korus | @skorusARK
Director of Research, Autonomous Technology & Robotics
ロケットの迅速な再利用は、打ち上げコストの削減と宇宙探査の推進に不可欠です。下図で示すように、昨年だけでも、SpaceX社はロケットの再利用期間を27日から21日に短縮しました。[1] もしコストが時間と相関しているとすれば、私たちの調査によると、ファルコン9ロケットの第1段の改修費用は、過去5年間で1,300万米ドルから100万米ドルに減少したことになります。この改善と他の再利用技術の開発により、地球低軌道までのキログラムあたりのコストは、新品のファルコン9が約2,700米ドルであるのに対し、再利用のファルコン9は800米ドル程度になると考えられます。歴史的な背景として、スペースシャトルの改修には、1回の打ち上げにつき4億5千万米ドルから15億米ドルの費用がかかりました。
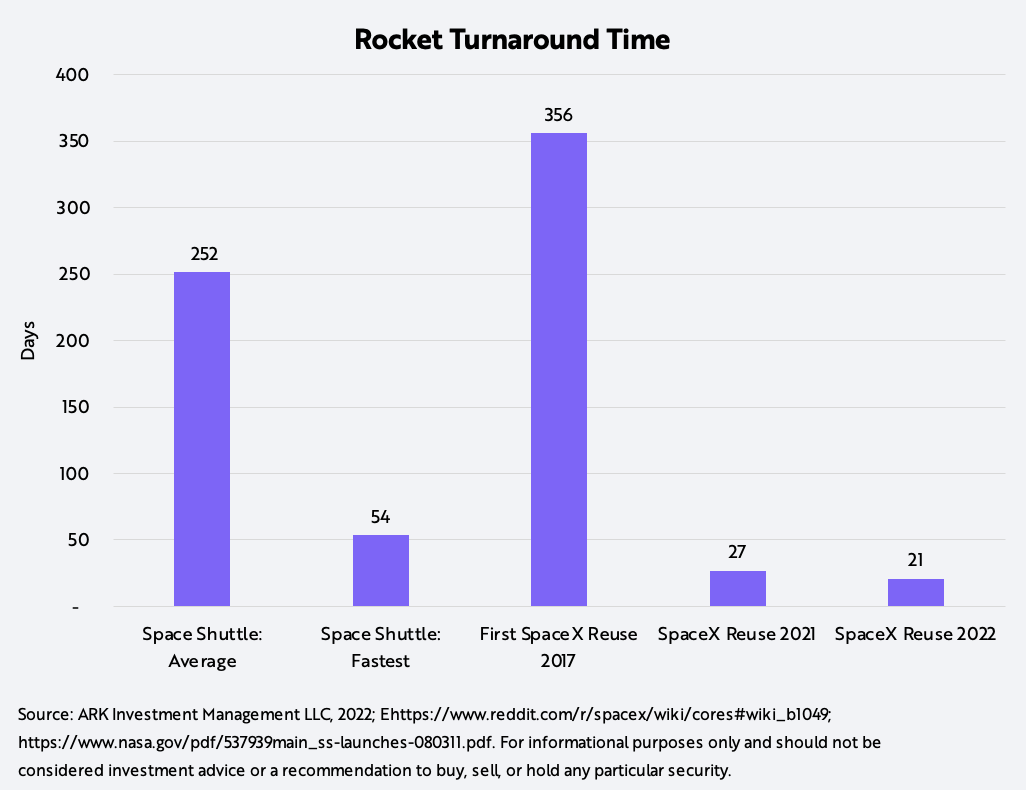
[1] 注目に値するのは、Rocket Lab(ロケットラボ)もまた最近、ロケットの再利用に向けた重要なマイルストーンを実行中であることを明らかにしたことです。
2. NVIDIAはヘルスケア分野における意思決定に関わるデータの活性化に向けて前進中
By Simon Barnett | @sbarnettARK
Director of Research, Life Sciences
元々はゲーム業界向けに開発されたグラフィック・プロセッシング・ユニット(GPU)は、現在ではディープラーニングなどの計算タスクを加速することができるようになりました。そして、これにより、NVIDIA社はライフサイエンス業界の重要な推進役へと変化したと考えられます。 GPUは、例えば、DNAシーケンサのようなライフサイエンス・ツールに関連する爆発的なデータを処理し、生物系の複雑さを分析することを可能にします。そして私たちは、ほとんどの生物学的研究と臨床ワークフローは、最終的にGPUで高速化された機械学習アルゴリズムがデフォルト設定になると考えています。先週、人工知能(AI)ハードウェアおよびソフトウェアシステムの世界的リーダーであるNVIDIA社は、急速に成長しているライフサイエンス業界向けの同社の研究エコシステムであるClaraへのいくつかの主要な機能強化を発表しました。
1 つ目は、生物医学研究機関のグローバルリーダーである Broad Institute(ブロード研究所) との新しいパートナーシップです。ブロード研究所は、DNA配列解析のためのNVIDIA社の「Clara Parabricks」ツールを独自のクラウドベース研究プラットフォーム「Terra」に統合し、世界中の何万人もの研究者を支援します。また同時に、NVIDIA社は、遺伝子変異を特定する業界標準のソフトウェアであるブロード研究所のGATKツールキットを、GPUベースの解析用に最適化します。ParabricksとTerraにより、研究者たちはGoogle (GOOGL)のDeepVariantのようなクラス最高のコミュニティ・アルゴリズムにアクセスすることができるようになるのです。 これにより、ライフサイエンス研究の主要プラットフォームとしての NVIDIA社の役割が確固たるものになると確信しています。
同社はまた、 大規模言語モデル(LLM)をライフサイエンス分野に適応させるフレームワークである「BioNeMo」も発表しました。Claraソフトウェアスイートで利用できるBioNeMoは、5,000億を超えるパラメータを持つNeMo Megatron LLMを活用して、DNA、RNA、タンパク質などの生体分子に関するニューラルネットワークモデルを構築するもので、AlphaFoldの機能によく似ています。 この技術により、参入障壁が下がり、ライフサイエンス研究者が生物学的問題に対応したLLMを開発・拡張できるようになり、新薬の発見・開発が加速されることでしょう。
こうした進歩のおかげで、ライフサイエンスにおけるデータの爆発的な増加が見込めるため、NVIDIA社は当面の間、重要な提携先として位置づけられることになると確信しています。
3. OpenAIがオープンソースの汎用音声認識モデルを発表
By William Summerlin | @summerlinARK
Analyst
先週、OpenAIは、人間に近いレベルのパフォーマンスで音声をテキストに書き起こすことができるオープンソースのニューラルネットワークをリリースしました。このリリースは、Stability.AI社のStable Diffusionモデルなど、最近注目されている他のオープンソースプロジェクトの展開に続くものです。
60万時間以上の音声データでトレーニングされたOpenAI社のWhisperモデルは、英語を英語以外の音声に変換したり、また逆に、英語以外の音声を英語の音声に変換することができます。大規模な言語モデルは、ますます膨大なテキストデータを必要とするようになり、正確な音声認識ツールは重要な学習データを活性化することが示唆されています。 そのため、WhisperのようなモデルがGPT-3のような大規模言語モデルとシームレスかつ正確にインターフェースするようになれば、音声データは人工知能の学習プロセスにとって不可欠なものになるはずです。

ARK’s statements are not an endorsement of any company or a recommendation to buy, sell or hold any security. For a list of all purchases and sales made by ARK for client accounts during the past year that could be considered by the SEC as recommendations, click here. It should not be assumed that recommendations made in the future will be profitable or will equal the performance of the securities in this list. For full disclosures, click here.